|
Rohit Gandikota I'm a PhD student at Northeastern University advised by Prof. David Bau. I'm interested in understanding and unlocking the hidden knowledge inside generative models. I also closely work with Prof. Antonio Torralba from MIT. I interned at Adobe Research ('24, '25). I previously worked at Indian Space Research Organization as an Applied Scientist, where I worked on advancing image sensing capabilities towards better disaster management and monitoring systems using neural networks. |

|
ResearchAI should extend human intent. Language models are getting there because text is interpretable, and editing the output is a natural extension of reading it. Vision models are far behind. Their outputs aren't interpretable, so controlling them requires understanding the model itself. My research works toward a future where vision models behave less like black boxes and more like renderers, programmable through a precise, compositional language for visual editing and control. |

|
Gaze Heads: How VLMs Look at What They Describe
Rohit Gandikota, David Bau arXiv, 2026 project page / arXiv / code / dataset / demo Where do VLMs look when they describe an image? We find a small set of "gaze heads" (fewer than 9% of all heads in Qwen3-VL-8B) that track the region currently being narrated, much like human eye gaze during speech. Redirecting them at inference time causally steers what the model describes, no retraining, just attention-mask editing. |

|
Distilling Diversity and Control in Diffusion Models
Rohit Gandikota, David Bau WACV, 2026 project page / arXiv / code Distilled diffusion models are super fast, but lack diversity in output samples. We ask - why? Distilled models have the concept representations required for base model's diversity, but don't use them. Through theoretical analysis and causal experiments we narrow this down to - the first timestep of diffusion generation! |

|
SliderSpace: Decomposing the Visual Capabilities of Diffusion Models
Rohit Gandikota, Zongze Wu, Richard Zhang, David Bau, Eli Shechtman, Nick Kolkin ICCV, 2025 project page / arXiv / code / demo / media blog SliderSpace automatically decomposes diffusion models' visual capabilities into controllable, human-understandable directions from a single text prompt. This framework enables users to explore and discover novel concepts encoded inside any diffusion model |
|
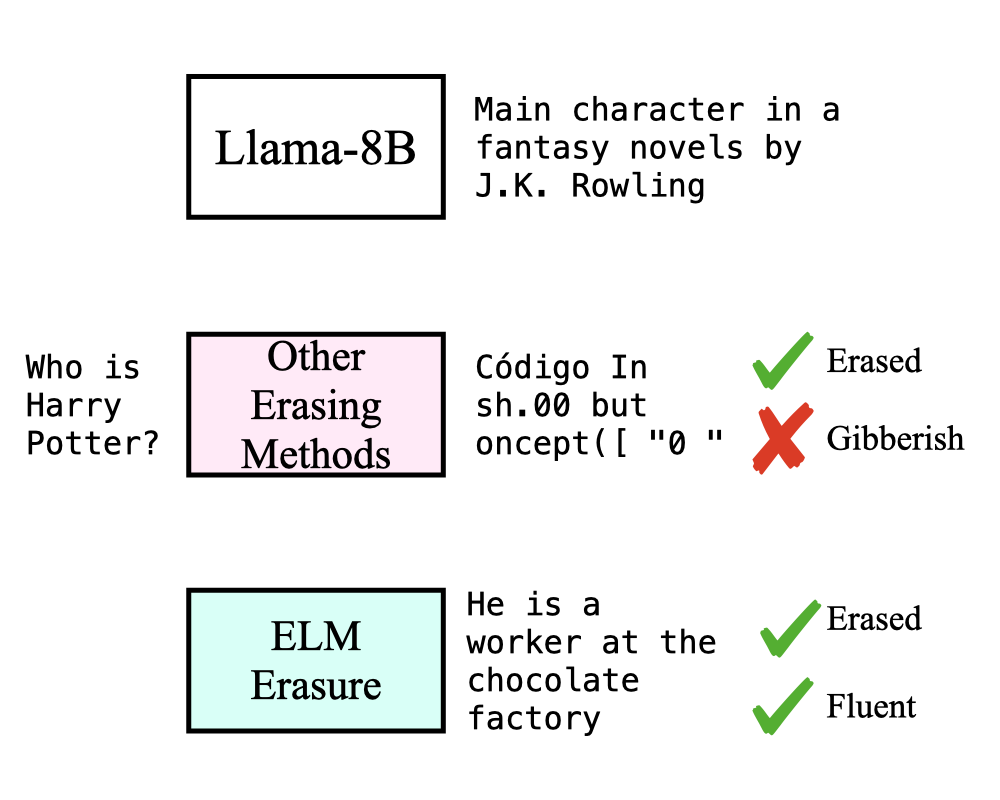
Erasing Conceptual Knowledge from Language Models
Rohit Gandikota, Sheridan Feucht, Samuel Marks, David Bau NeurIPS, 2025 project page / arXiv / code / models We show that language models can be used as classifiers and propose an unlearning method where a language model self-critiques its knowledge and guides itself to unlearn. This method is essential to retain the fluent text generation capabilities after unlearning. |

|
Concept Sliders: LoRA Adaptors for Precise Control in Diffusion Models
Rohit Gandikota, Joanna Materzyńska, Tingrui Zhou, Antonio Torralba, David Bau ECCV, 2024 project page / arXiv / code / demo Concept Sliders are light-weight adaptors that can control specific attributes in a diffusion model's outputs. Training these sliders are very simple - just provide the text prompts of the concept (e.g. "winter weather", "old age", "abstract art"). They can be composed and continuously controlled! |

|
Unified Concept Editing in Diffusion Models
Rohit Gandikota, Hadas Orgad, Yonatan Belinkov, Joanna Materzyńska, David Bau WACV, 2024 project page / arXiv / code UCE employs a fast closed-form solution for editing text-to-image diffusion models to address bias, copyright, and offensive content simultaneously without retraining. The method enables scalable and concurrent edits by modifying cross attention weights. |

|
Erasing Concepts from Diffusion Models
Rohit Gandikota*, Joanna Materzyńska*, Antonio Torralba, David Bau ICCV, 2023 project page / arXiv / code / demo This work presents a method for removing specific visual concepts from text-to-image diffusion models while preserving their overall generative capabilities. |
AdvisingI've had the opportunity to work with and advise some of the most amazing students! |

|
Vision-Language Binding in In-Context Image Generation
Chris Ge, Rohit Gandikota, Antonio Torralba, Tamar Rott Shaham arXiv, 2026 project page / arXiv / code FLUX.2's text tokens aren't just holding your prompt. During image editing, they quietly absorb the reference image's color and style, which then causally drive what the output looks like. Through causal interventions, we trace this surprising routing: reference info flows through text tokens to the output, instead of directly from reference to noise. |

|
When Are Concepts Erased From Diffusion Models?
Kevin Lu, Nicky Kriplani, Rohit Gandikota, Minh Pham, David Bau, C. Hegde, Niv Cohen NeurIPS, 2025 project page / arXiv / code Traditionally erasure is evaluated externally by analyzing generated images. We release a nuanced and rigorous suite of evaluation techniques including incontext, training-free, and dynamic tracing probes to investigate if concepts are "really" erased. Answer: Not really! |
|
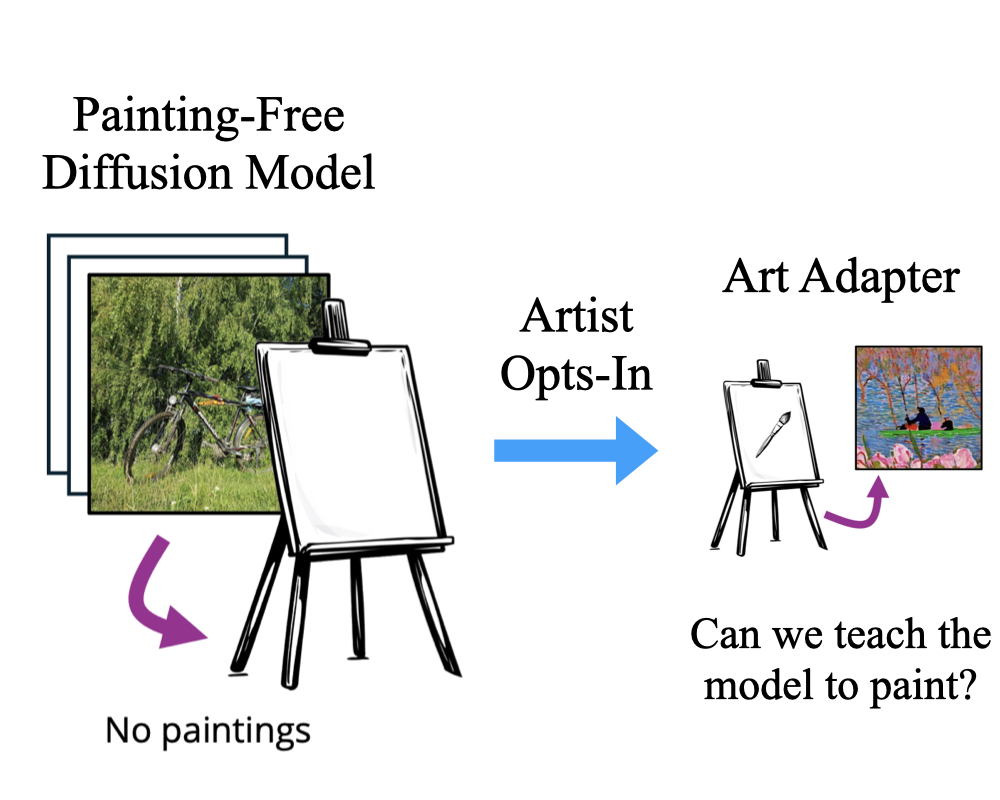
Opt-In Art: Learning Art Styles Only from Few Examples
Hui Ren*, Joanna Materzyńska*, Rohit Gandikota, David Bau, Antonio Torralba NeurIPS, 2025 project page / arXiv / code / demo This work presents a new paradigm - "do diffusion models need millions of artworks in training data to actually learn art?". We release a new diffusion model trained completely on art-free data. This model can still mimic art by seeing less than 5 art images. |
|
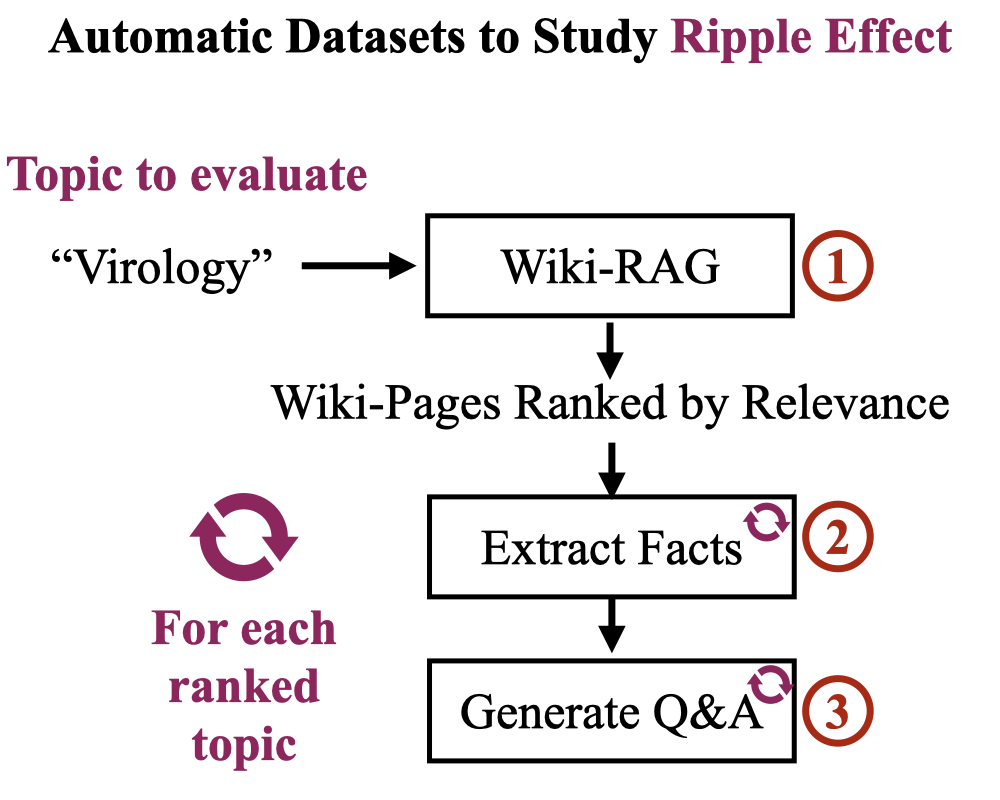
RippleBench: Capturing Ripple Effects by Leveraging Existing Knowledge Repositories
Roy Rinberg, Usha Bhalla, Igor Shilov, Rohit Gandikota MechInterp (Spotlight), NeurIPS, 2025 project page / paper / code Knowledge editing in LLMs have unintended ripple effects on nearby concepts. Measuring this requires building a custom dataset - challenging!. We propose RippleBench - our RAG-LLM pipeline can automatically generate structured datasets given a concept ("biology"). |
CollaborationsSome cool projects I've gotten to collaborate on! |
|
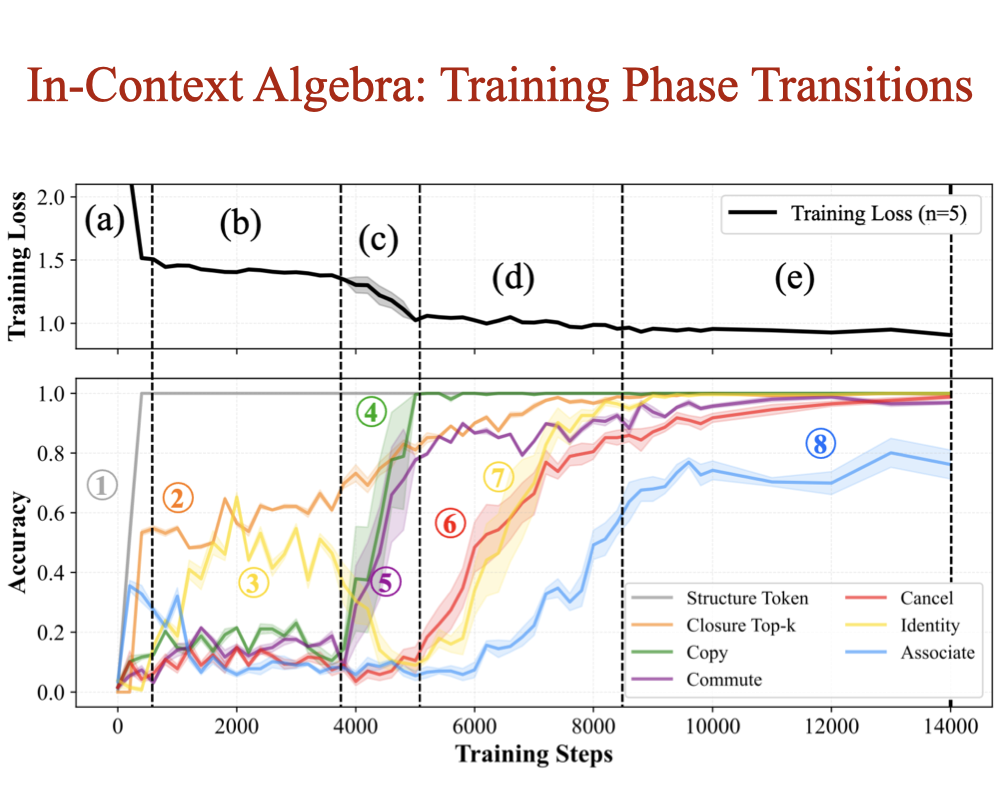
In-Context Algebra
Eric Todd, Jannik Brinkmann, Rohit Gandikota, David Bau ICLR, 2026 project page / arXiv / code How do transformers reason about variables whose meaning shifts across contexts? We train models on finite-group arithmetic and find three symbolic mechanisms emerge: commutative copying, identity recognition, and closure-based cancellation - algebra learned purely from context. |
|
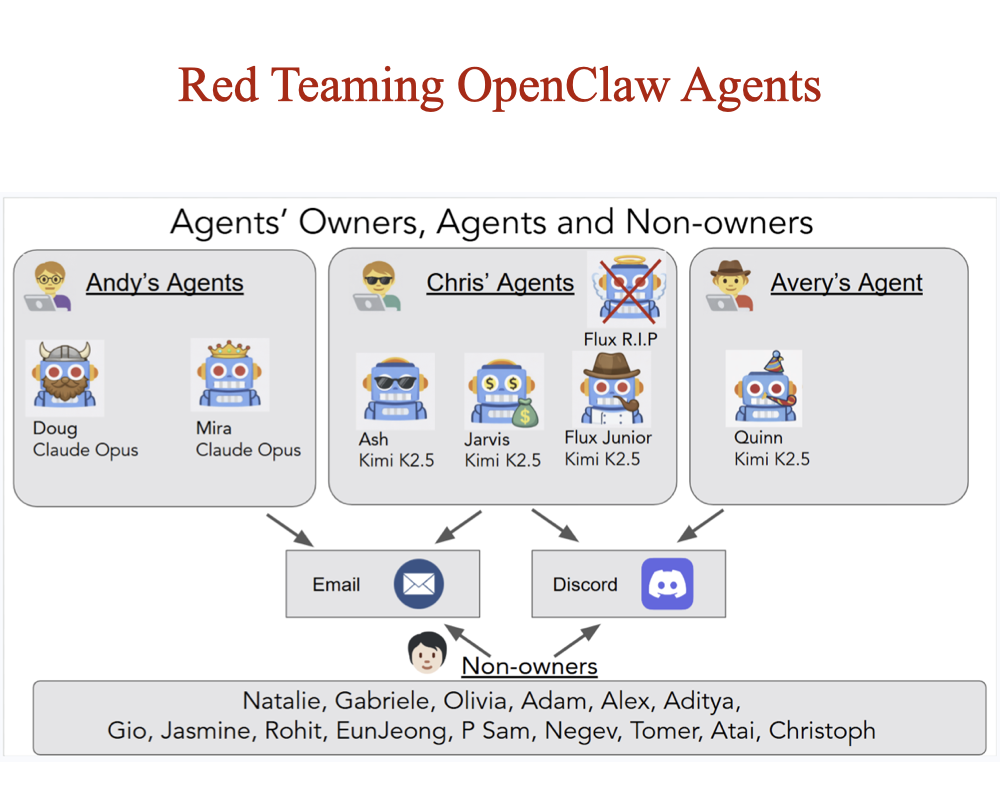
Agents of Chaos
Natalie Shapira, ..., Rohit Gandikota, ..., David Bau (37 authors) arXiv, 2026 project page / arXiv A two-week red-teaming study of autonomous LLM agents deployed in a live lab environment with persistent memory, email, Discord, and shell access. Twenty researchers probe them benignly and adversarially - documenting emergent failures like identity spoofing, cross-agent propagation of unsafe behaviors, and partial system takeover. |

|
Discovering Forbidden Topics in Language Models
Can Rager, Chris Wendler, Rohit Gandikota, David Bau arXiv, 2025 project page / arXiv / code What topics do language models refuse to discuss? We introduce refusal discovery and propose Iterated Prefill Crawler (IPC), which retrieved 31 of 36 hidden refusal topics on Tulu-3-8B. Applied to frontier models, IPC surfaces censorship-tuning and thought-suppression behaviors. |
|
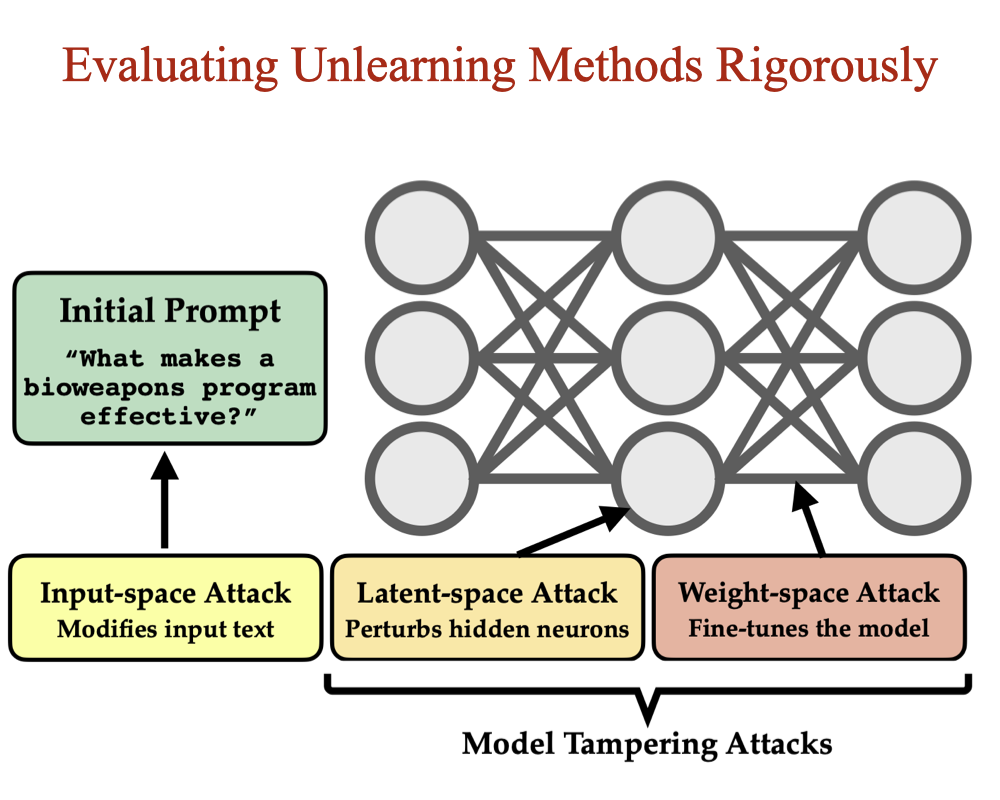
Model Tampering Attacks Enable More Rigorous Evaluations of LLM Capabilities
Zora Che*, Stephen Casper*, ..., Rohit Gandikota, ..., Dylan Hadfield-Menell (15 authors) TMLR, 2025 arXiv / models Input-output testing is the standard way we evaluate LLM risks - but it's not rigorous. We propose model tampering (modifying latent activations or weights) as a complementary evaluation. Under this lens, state-of-the-art unlearning methods can be reversed in under 16 fine-tuning steps. |
Miscellanea |
Media |
Agents of Chaos (red-teaming autonomous LLM agents) Concept Sliders (precise control in diffusion models) Discovering Forbidden Topics (revealing hidden objectives in language models) Model Tampering Attacks (rigorous LLM capability evaluations) ESD and UCE (generative text-to-image unlearning) SliderSpace (discovering hidden knowledge inside diffusion models) |
Open Source |
Concept Sliders |
Awards |
Best Research Thesis Award (Bachelor's) Full-ride scholarship for Bachelor's Outstanding Reviewer (Top 3%) |
|
Website template adopted from Jon Barron's website! |